Mike
Moderator
Hi all,
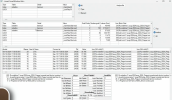
I have a question about long running transactions of database by using R&D and active transaction. We always having transaction number like below:-
45 Rxcm -4 SELF/ABL 06/03/25 08:27 06/03/25 13:20 1746518328 Active
But it is not giving complete info like what table or source code is causing this long running or lock table. Which code is user using complete info of code or program user using. If there any chance to know what table or source code is causing this long running or lock table?
Thanks regards
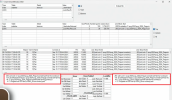
I have a question about long running transactions of database by using R&D and active transaction. We always having transaction number like below:-
45 Rxcm -4 SELF/ABL 06/03/25 08:27 06/03/25 13:20 1746518328 Active
But it is not giving complete info like what table or source code is causing this long running or lock table. Which code is user using complete info of code or program user using. If there any chance to know what table or source code is causing this long running or lock table?
Thanks regards
")